上篇文章介绍了介绍了Fluentd以及EFK机制,最近了解了Elasticsearch,在这里做一个总结
Elasticsearch is a search engine based on Lucene. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java and is released as open source under the terms of the Apache License. Official clients are available in Java, .NET (C#), PHP, Python, Apache Groovy, Ruby and many other languages. According to the DB-Engines ranking, Elasticsearch is the most popular enterprise search engine followed by Apache Solr, also based on Lucene.
Elasticsearch是一个基于Lucene的搜索引擎。它提供了一个分布式、多用户全文搜索引擎,有着HTTP Web界面和无结构JSON文档。Elasticsearch是用Java开发的,并根据Apache License的条款作为开源发布。官方客户端有Java,.NET(C#),PHP,Python,Apache Groovy,Ruby和许多其他语言版本。根据DB-Engines排名,Elasticsearch是最受欢迎的企业搜索引擎,后面是基于Lucene的Apache Solr。——摘自维基百科
什么是全文搜索?全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,根据索引可以找到文档。我们使用的百度、谷歌等搜索引擎,就是基于这个技术对所有爬取的万维网网页做拆分建立建立全文索引,当我们输入关键字时给我们展现相关的页面。当然,商业搜索引擎还采用竞价排名、PageRank等复杂的算法。
Elasticsearch是基于开源库Lucene的封装,Lucenej接口使用较为复杂,Elasticsearch使用会更加简单。要明白Elasticsearch机制,首先得搞清楚Lucene是什么。
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。 ——摘自百度百科
Lucene全词匹配索引的关键技术是用到了FST(Finite State Transducer)——有穷状态转换器。在自然语言处理等领域有很大应用,其功能类似于字典的功能(STL 中的map,C# 中的Dictionary),但其查找是O(1)的,仅仅等于所查找的key长度。目前Lucene4.0在查找Term时就用到了该算法来确定此Term在字典中的位置。
关于FST的介绍,可以看这篇博文lucene源代码学习之FST(Finite State Transducer)在SynonymFilter中的实现思想
Kibana使用
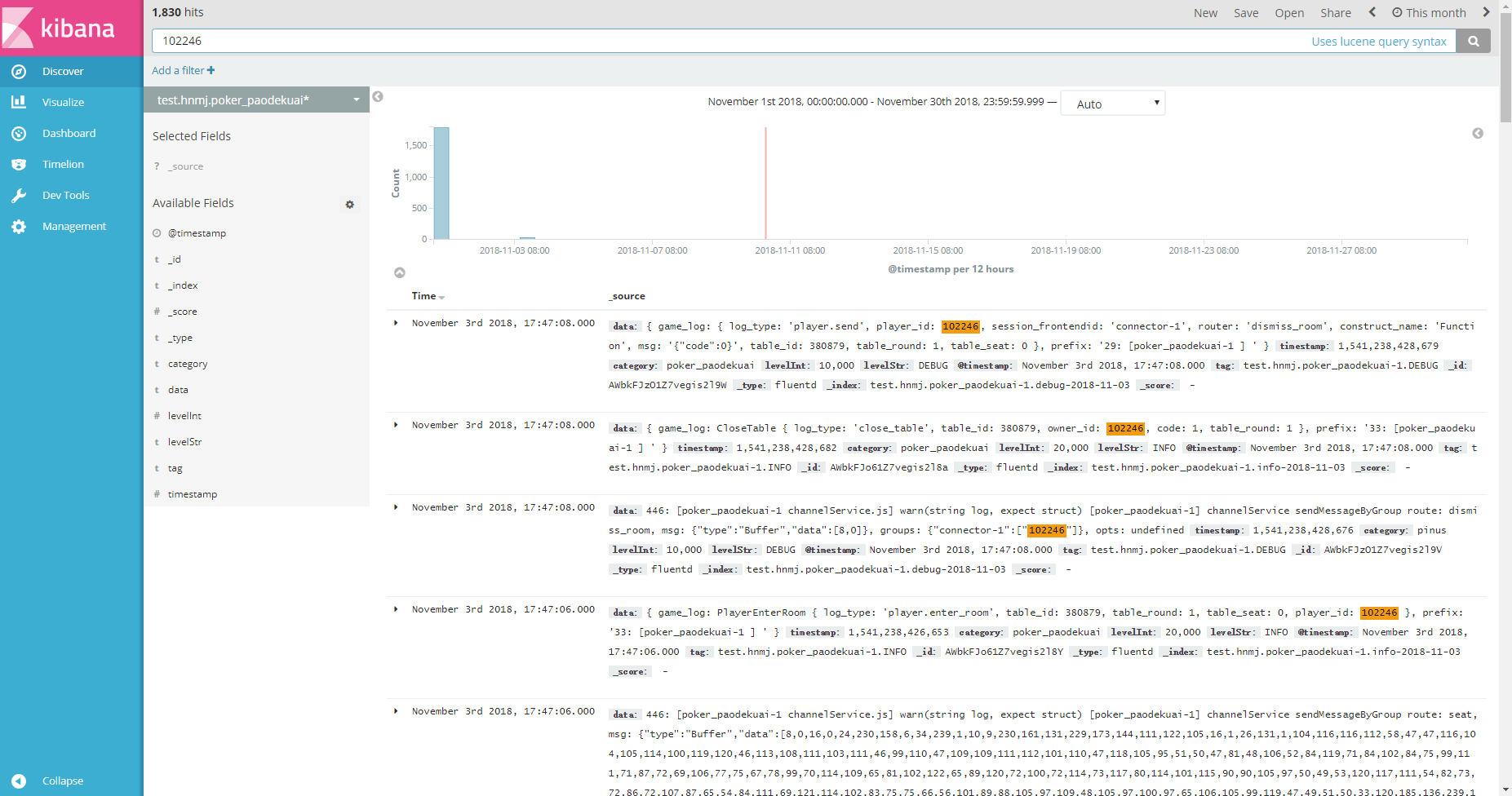
搜索102246,页面呈现包含搜索字段结果,上方还有以时间为横坐标、log条目为纵坐标的柱状图。